Hybrid RAG API with LangChain, Qdrant & Redis Caching
Retrieval-Augmented Generation (RAG) is only as good as its retrieval. Pure keyword search can miss semantic matches, and pure vector search can miss exact terms, identifiers, and edge-case strings. This API combines both with hybrid retrieval and adds Redis caching so repeated questions return in milliseconds.
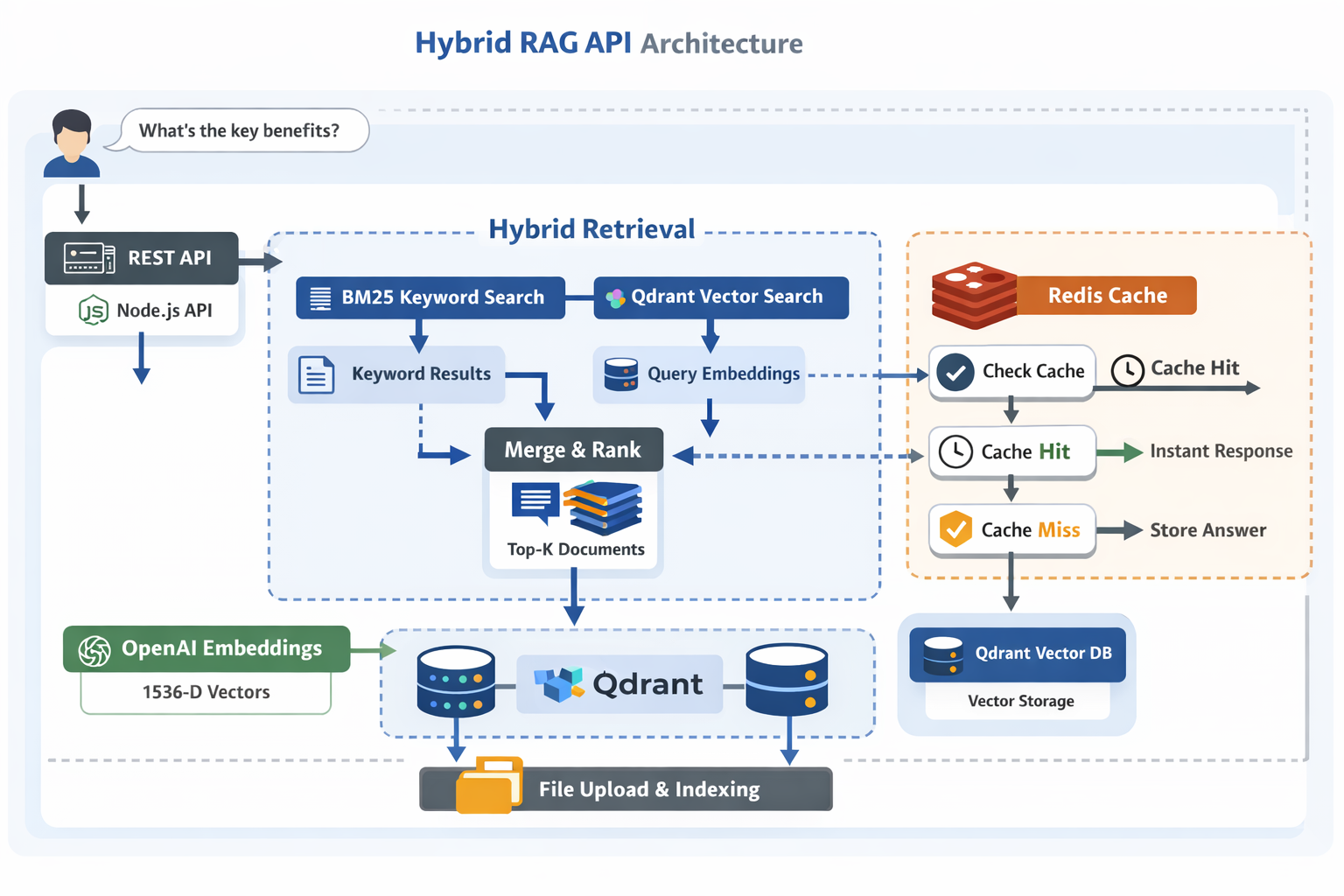
What it does
- Upload
.txtfiles and automatically index them for retrieval - Split text into chunks (500 chars, 150 overlap)
- Run hybrid search:
- BM25 for keyword matching
- Qdrant for semantic similarity (cosine distance)
- Use OpenAI embeddings (
text-embedding-3-small, 1536 dims) - Generate answers with Anthropic Claude
- Cache Q&A in Redis (24h TTL) with stats and invalidation on re-upload
Why hybrid retrieval
Hybrid retrieval usually improves quality because it can handle:
- Exact strings (IDs, error messages, filenames, code symbols) via BM25
- Paraphrases and conceptual matches via vector search
- Better ranking stability when either approach alone is noisy
The final result list is merged by normalizing scores, applying weights, and selecting the top (k) contexts.
Local setup
Install:
pnpm install
Create .env:
pnpm run setup
Required keys:
# Anthropic API key ANTHROPIC_API_KEY=your_anthropic_api_key_here # OpenAI API key for embeddings OPEN_AI_API_KEY=your_openai_api_key_here
Optional Redis:
REDIS_HOST=localhost REDIS_PORT=6379 REDIS_PASSWORD=your_redis_password_here
Optional Qdrant:
QDRANT_HOST=localhost QDRANT_PORT=6333 QDRANT_COLLECTION_NAME=documents
Hybrid tuning:
HYBRID_SEARCH_BM25_WEIGHT=0.5 HYBRID_SEARCH_VECTOR_WEIGHT=0.5 HYBRID_SEARCH_TOP_K=8
Usage
Dev:
pnpm run dev
Prod:
pnpm run build pnpm start
Test the chain:
pnpm test
API endpoints
POST /upload-file: upload a.txtfile, index it, and invalidate related cachePOST /ask-question:{ "filename": "...", "question": "..." }- cache hit → return instantly
- cache miss → hybrid retrieve → Claude → cache result → return
GET /cache-stats: Redis cache/memory statsDELETE /delete-cache: clear cached Q&A for a file
How it works (high-level)
Question → Check Redis Cache → Cache Hit? → Return Cached Answer ↓ Cache Miss ↓ ┌───────────────────┐ │ Hybrid Retriever │ └─────────┬─────────┘ │ ┌─────────┴─────────┐ │ │ BM25 Search Vector Search (Keyword) (Semantic) │ │ │ Query → Embeddings │ │ │ Qdrant Vector DB │ │ └─────────┬─────────┘ │ Merge & Rank Results (Normalize + Weight) │ Top K Documents → Claude → Cache → Response
Implementation map
src/anthropic/index.ts: RAG chain implementationsrc/routes/langchain-router.ts: endpoints + Redis integrationsrc/lib/hybrid-retriever.ts: BM25 + vector merging/rankingsrc/lib/qdrant.ts: Qdrant servicesrc/lib/embeddings.ts: OpenAI embeddingssrc/lib/redis.ts: caching layer (TTL, keying, stats)src/lib/storage.ts: file storage utilitiessrc/constants.ts: config knobs (Redis/Qdrant/hybrid weights)